Imagine asking your company’s AI assistant about a policy buried 47 pages deep in a PDF — and getting the right answer, with the exact source cited. No hallucination. No vague summary. Just precise, grounded information. That’s the promise of RAGFlow, and it’s one of the most exciting open-source AI projects you probably haven’t heard enough about.
“RAGFlow is a leading open-source Retrieval-Augmented Generation (RAG) engine that fuses cutting-edge RAG with Agent capabilities to create a superior context layer for LLMs.”
⭐ 73,200+ GitHub stars || 🍴 8,100+ forks || 👥 483 contributors || 📦 Apache 2.0 license
What is RAGFlow?
RAGFlow — built by the team at Infiniflow — is an open-source Retrieval-Augmented Generation (RAG) engine. At its core, RAG is a technique that lets AI language models answer questions by first retrieving relevant information from your own documents, databases, or data sources, then generating an answer grounded in that retrieved content.
What makes RAGFlow stand out from the dozens of RAG frameworks out there is its emphasis on quality at every step of the pipeline. It doesn’t just chunk documents and call it a day. It deeply understands document structure, preserves semantic meaning, and gives you full visibility into why the model said what it said.
The Problem RAGFlow Solves
Most enterprise AI projects hit a wall when it comes to grounding LLMs in company knowledge. The typical approach — dump some PDFs into a vector database, do a similarity search, stuff the results into a prompt — works fine for demos. It falls apart in production.
The issues are familiar to anyone who’s shipped a RAG system:
- PDFs with complex layouts (tables, multi-column text, images) get mangled during extraction
- Naive chunking cuts context at arbitrary points, splitting sentences or paragraphs that belong together
- No way to trace which document chunk led to a given answer
- Hallucinations sneak in when retrieved chunks are marginally relevant
RAGFlow is designed specifically to address these failure modes — not as an afterthought, but as the foundational design principle.
Key Features Worth Knowing
🔍 Deep Document Understanding
Parses complex document formats — PDFs, Word, Excel, scanned images, slides — preserving structure and meaning, not just raw text.
✂️ Template-Based Chunking
Intelligent chunking with multiple templates. Choose the strategy that fits your document type, not a one-size-fits-all split.
📌 Grounded Citations
Every answer comes with traceable references. Users can see exactly which passage the model pulled from, eliminating mystery.
🤖 Agentic Workflows
Goes beyond simple Q&A. Build multi-step AI agents with pre-built templates, Python/JS code executors, and MCP support.
🔌 Flexible LLM Support
Works with OpenAI, DeepSeek, Gemini, and many others. Configurable embedding models and re-ranking strategies.
🌐 Multi-Source Ingestion
Sync data from Confluence, Notion, Google Drive, S3, Discord, and more. Supports cross-language queries out of the box.
How It Works: The RAGFlow Pipeline
RAGFlow’s architecture can be thought of in three phases: ingestion, retrieval, and generation.
1. Ingestion — Where quality begins
When you upload a document, RAGFlow runs it through its DeepDoc engine — a proprietary document understanding layer that goes far beyond basic text extraction. It recognizes tables, figures, headers, footers, and multi-column layouts. For scanned documents, OCR is applied with layout awareness, not just raw character recognition.
You then choose a chunking template: general, Q&A, resume, paper, book, laws, manual, and more. Each template is optimized for how that type of content is typically structured and queried.
2. Retrieval — Finding the needle
RAGFlow supports multiple recall strategies — dense vector search, sparse keyword search, and hybrid approaches — combined with fused re-ranking. This means a single query can leverage the strengths of semantic similarity and exact keyword matching simultaneously, dramatically improving recall for edge cases that pure vector search misses.
3. Generation — Grounded answers
The final response is generated with direct references back to the source chunks. Users see highlighted passages from the original documents, making it easy to verify claims and build trust in the system’s outputs.
💡 New in recent versions: RAGFlow now supports multi-modal understanding — it can use vision-capable LLMs to interpret charts, diagrams, and figures embedded in PDFs and Word documents, not just the surrounding text.
Getting Started: Deploying RAGFlow
RAGFlow ships as a Docker-based deployment. Here are the system requirements before you begin:
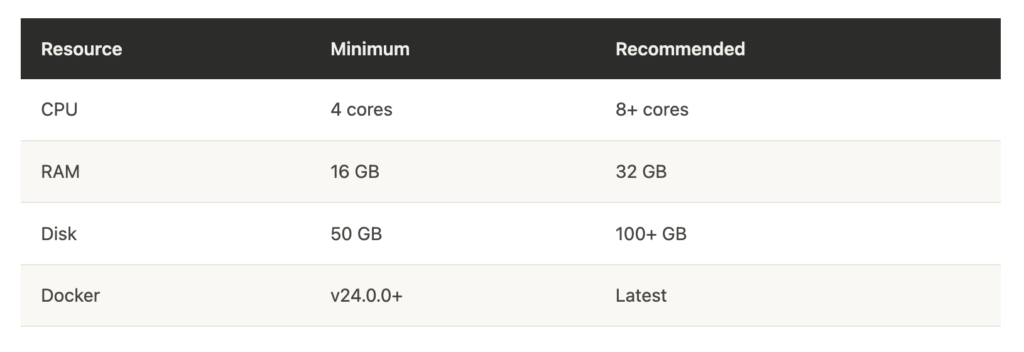
Once prerequisites are met, setup is straightforward:
# Clone the repository git clone https://github.com/infiniflow/ragflow.git cd ragflow/docker # Start with Docker Compose (CPU mode) docker compose -f docker-compose.yml up -d # Check logs to confirm successful launch docker logs -f docker-ragflow-cpu-1After the containers are running, navigate to http://YOUR_SERVER_IP in a browser, add your LLM API key in the service configuration, and you’re ready to start ingesting documents.

RAGFlow vs. the Alternatives
The RAG tooling space is crowded. Here’s how RAGFlow compares to other popular options:

The key differentiator: RAGFlow is a full application, not just a library. For teams that want to ship a production knowledge base without stitching together a dozen components, that matters enormously.
Who Should Use RAGFlow?
RAGFlow is a strong fit for several use cases:
Enterprise knowledge bases. If your organization has years of institutional knowledge locked in PDFs, SharePoint folders, and scattered documents, RAGFlow provides the infrastructure to make that knowledge queryable via AI — with the citations needed for compliance and trust.
Technical documentation assistants. Developer tools companies can use RAGFlow to build “ask your docs” interfaces that give precise, referenced answers from API documentation, runbooks, and internal wikis.
Legal and financial research. The citation-first design and high-fidelity document parsing make it particularly valuable in fields where accuracy and source traceability are non-negotiable.
Researchers and data scientists. The open-source nature and REST API make it an excellent experimentation platform for teams exploring RAG architectures without building from scratch.
“The best RAG system isn’t the one with the smartest model — it’s the one where users trust the answers.”
What’s Next for RAGFlow?
The project is actively maintained, with a public roadmap for 2026. Recent additions include memory support for AI agents, MCP (Model Context Protocol) integration for connecting external tools, and support for orchestrable ingestion pipelines. The team has also added native support for GPT-5, Gemini 3 Pro, and DeepSeek models.
With 73,000+ GitHub stars and nearly 500 contributors, RAGFlow has clearly struck a nerve. It’s filling a real gap between “RAG tutorial” and “production RAG system” — and doing it in the open.
Getting Involved
The project welcomes contributions of all kinds — bug reports, documentation improvements, new document loaders, and feature suggestions. The community is active on both Discord and GitHub Discussions.
If you want to experiment before self-hosting, there’s a live demo at demo.ragflow.io where you can try uploading documents and running queries right in the browser.
Ready to explore RAGFlow?
Star the repository on GitHub and follow the quickstart guide to get your first knowledge base running in under 30 minutes.